在 AI 应用开发中,让代理拥有持久化记忆能力一直是个技术难点。今天分享一个完整的实战项目:使用 Graphiti 构建实时知识图谱,让 AI 代理具备真正的”记忆”能力。
环境搭建:Neo4j 数据库安装
1. 下载安装 Neo4j
访问 https://neo4j.com/download/ 下载 Neo4j,安装完成后打开应用。
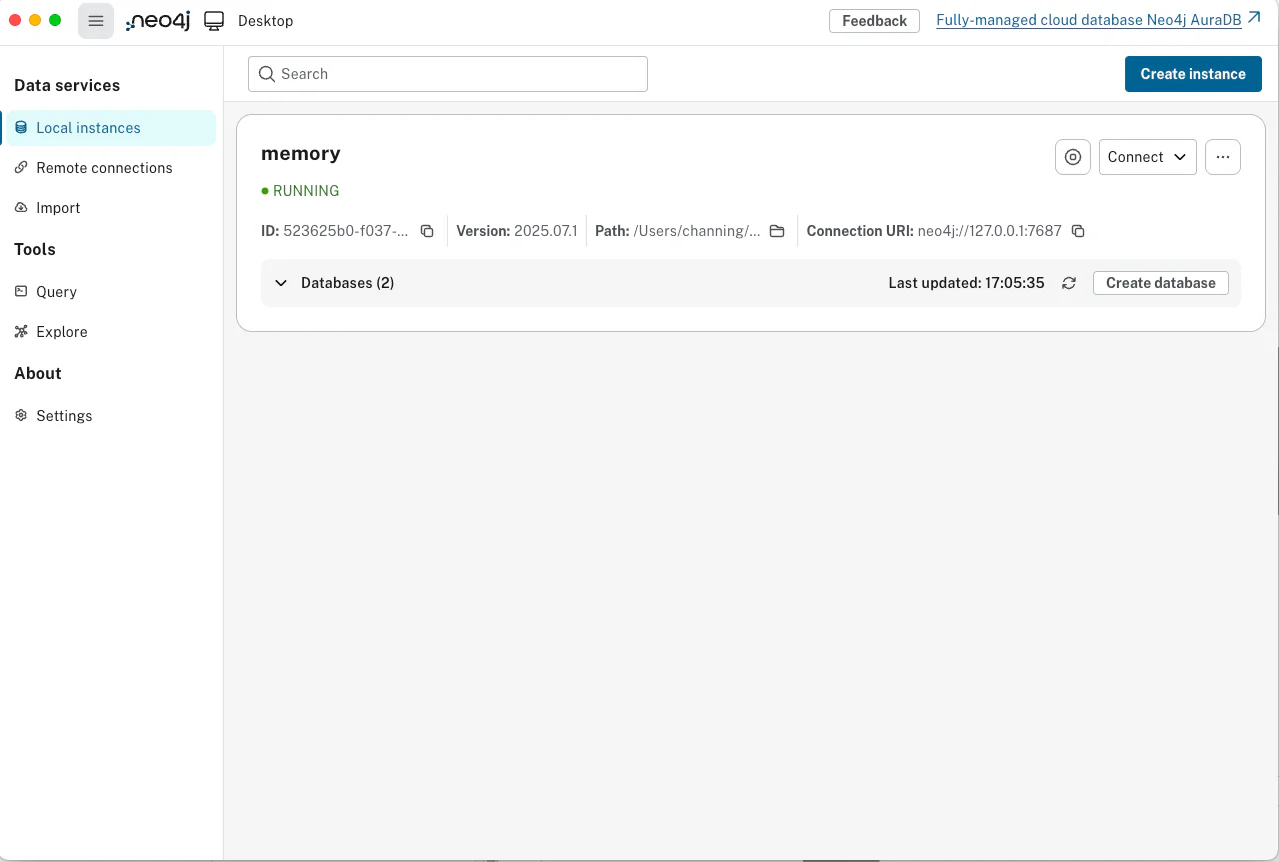
点击 Create Instance 按钮创建实例,等待实例创建完成。
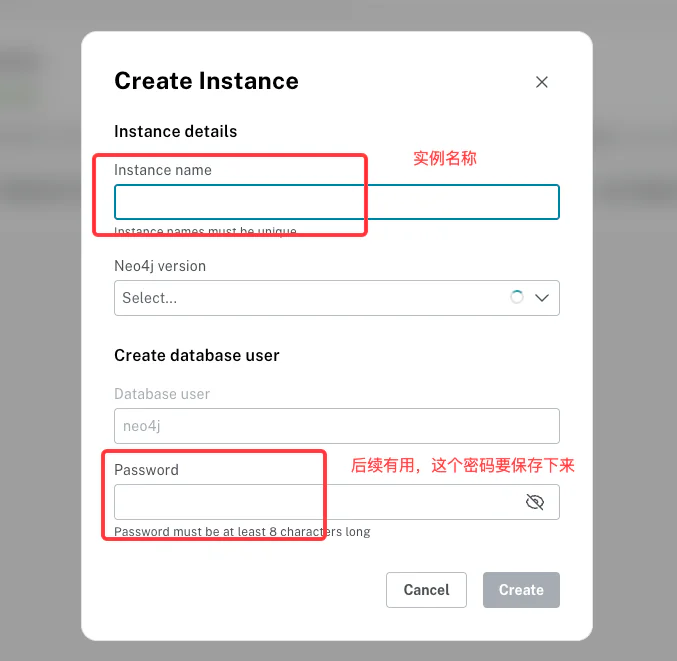
服务创建成功后,状态显示为 RUNNING:
2. 验证安装
访问 http://localhost:7474/browser/preview/ 进行验证:
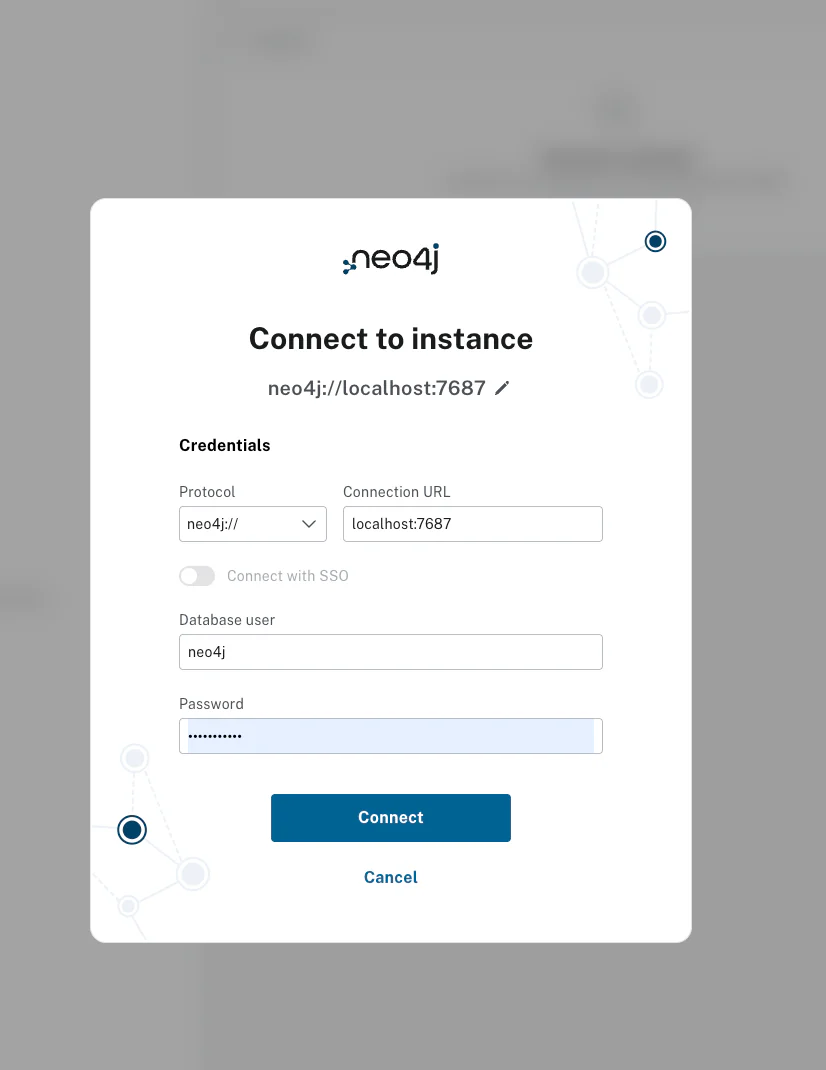
输入刚才设置的密码,成功进入主页面:
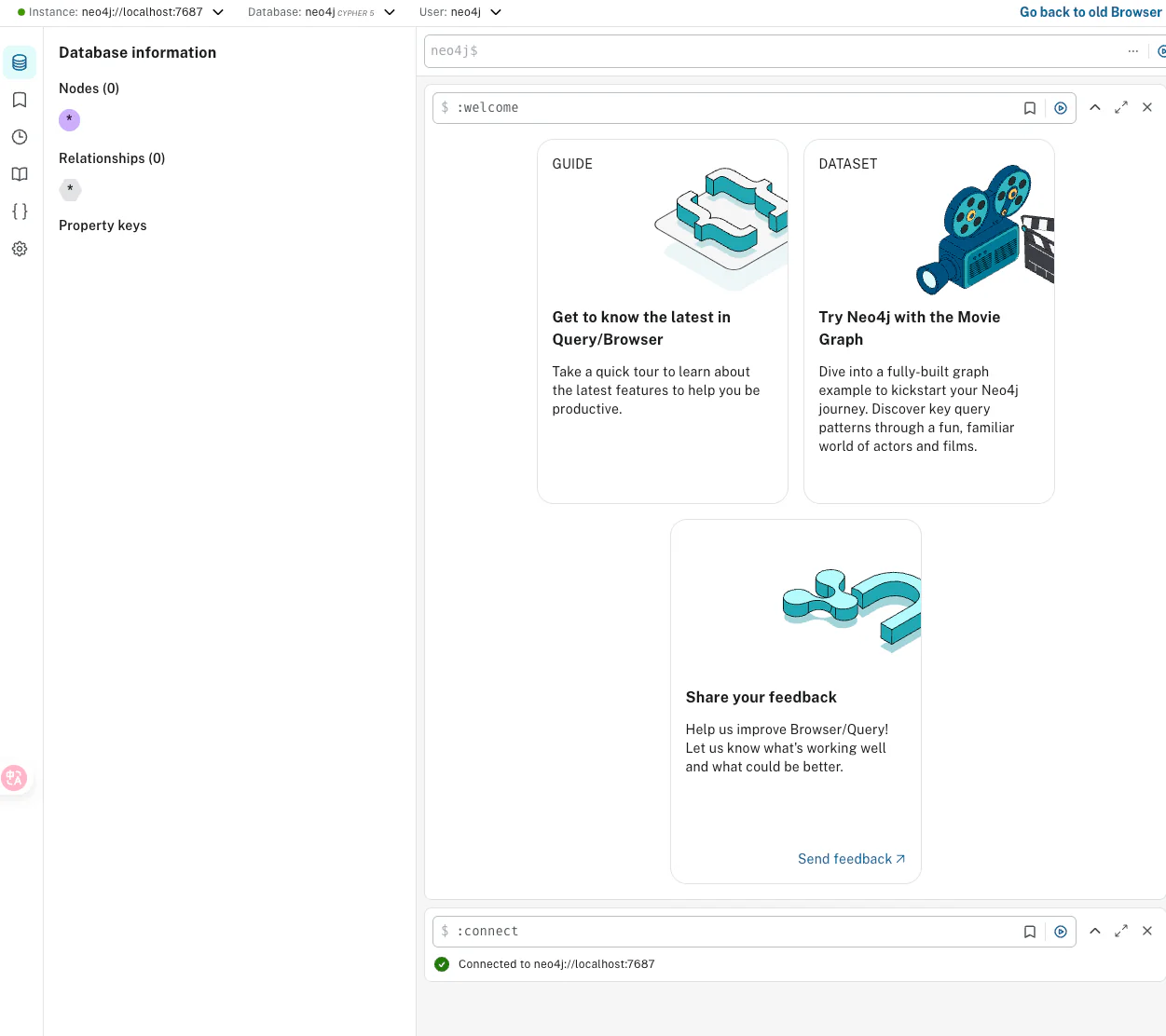
Neo4j 创建成功!
3. 环境变量配置
1
2
3
4
|
export NEO4J_URI="bolt://localhost:7687"
export NEO4J_USER="neo4j"
export NEO4J_PASSWORD="你的实际密码"
|
Graphiti 项目配置
1. 安装 Graphiti
1
2
3
4
5
6
|
uv init graphiti-project
cd graphiti-project
uv add graphiti-core
|
2. 克隆官方项目
1
| git clone https://github.com/getzep/graphiti.git
|
项目地址:https://github.com/getzep/graphiti?tab=readme-ov-file
3. 配置 LLM 密钥
复制.env.example 文件,命名为.env
在 .env 文件中添加完整配置(以下为脱敏后的配置示例):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
OPENAI_API_KEY=your_openai_api_key_here
AZURE_OPENAI_API_KEY=your_azure_openai_api_key_here
AZURE_OPENAI_ENDPOINT=https://your-endpoint.openai.azure.com/
AZURE_OPENAI_API_VERSION=2024-10-21
AZURE_OPENAI_DEPLOYMENT_NAME=gpt-4o-mini
AZURE_OPENAI_EMBEDDING_ENDPOINT=https://your-endpoint.openai.azure.com/
AZURE_OPENAI_EMBEDDING_API_VERSION=2024-10-21
AZURE_OPENAI_EMBEDDING_DEPLOYMENT_NAME=text-embedding-3-small
NEO4J_URI=bolt://localhost:7687
NEO4J_USER=neo4j
NEO4J_PASSWORD=your_neo4j_password
GRAPHITI_GROUP_ID=default
SEMAPHORE_LIMIT=
MAX_REFLEXION_ITERATIONS=
|
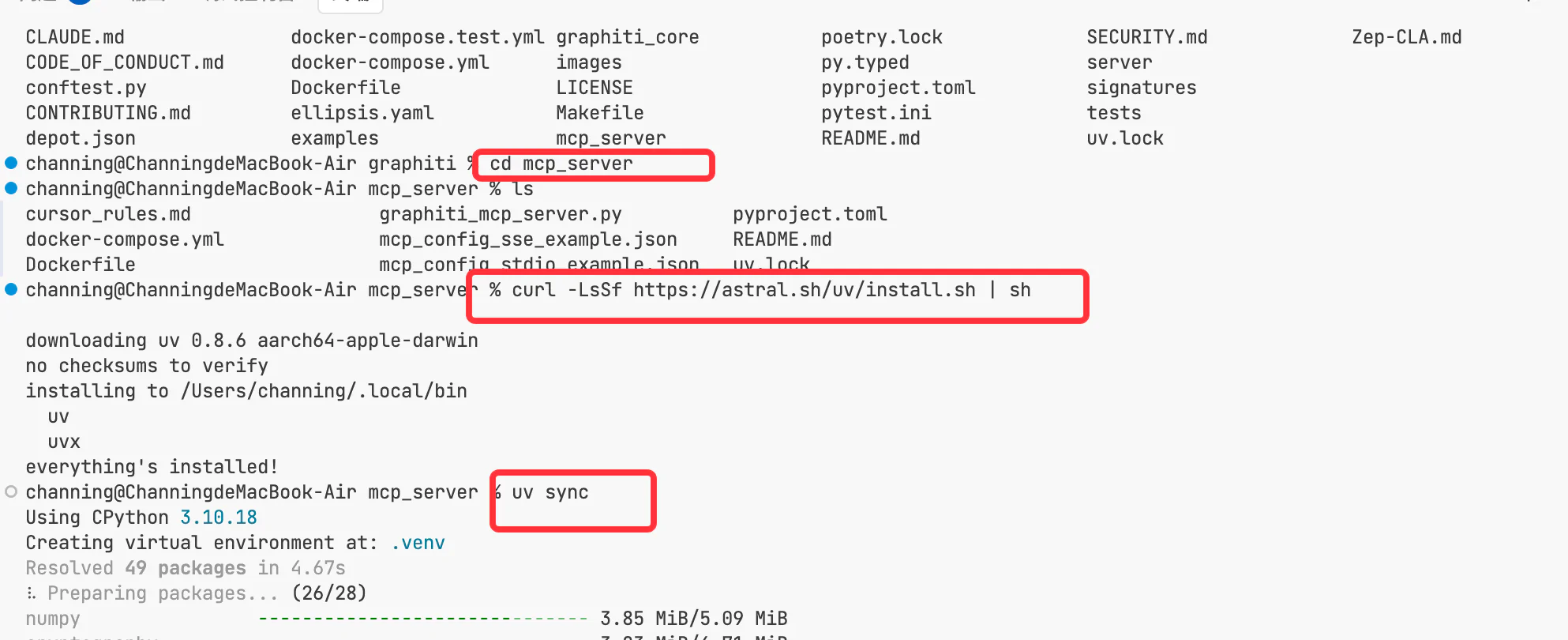
进入 mcp_server 目录,使用 uv 创建虚拟环境并安装依赖:
1
2
3
4
5
|
curl -LsSf https://astral.sh/uv/install.sh | sh
uv sync
|
实际操作效果:
启动与调试
1. 首次启动
1
| uv run graphiti_mcp_server.py
|
预期问题:首次启动会报错,需要补充环境变量:
1
2
| SEMAPHORE_LIMIT=20
MAX_REFLEXION_ITERATIONS=5
|
2. 成功启动
补充配置后再次启动:
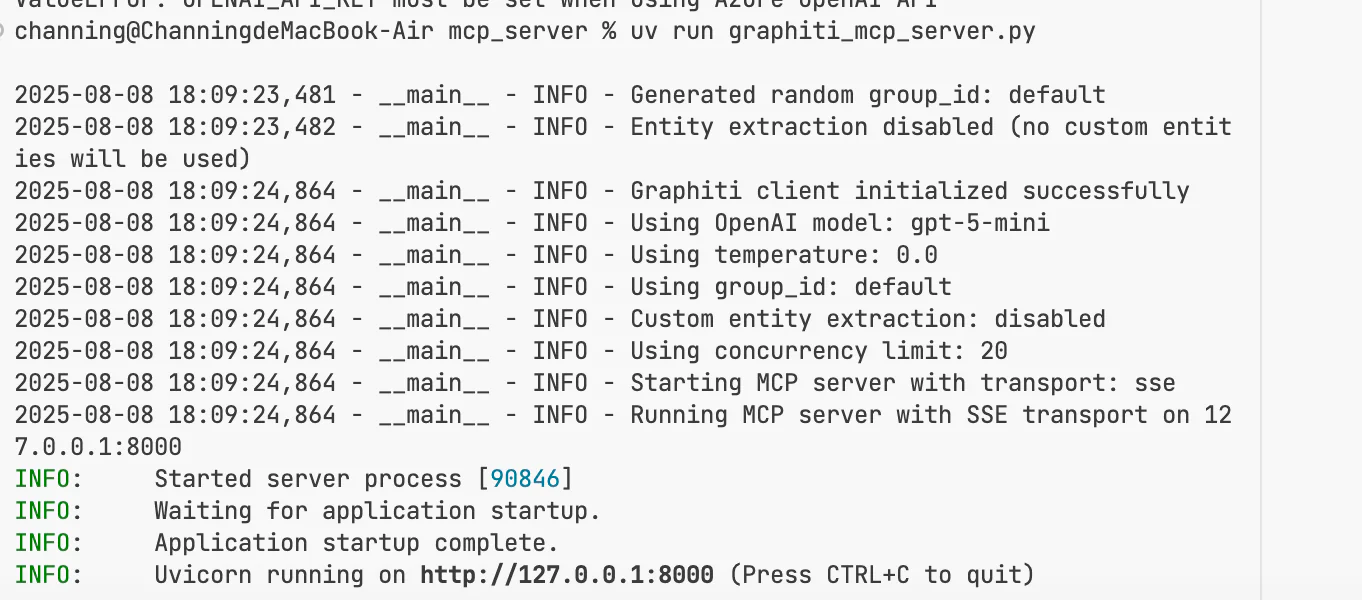
客户端集成测试
1. MCP 连接配置
在客户端(如 Claude Desktop)中通过 SSE 方式连接:
1
2
3
4
5
6
7
8
| {
"mcpServers": {
"graphiti": {
"transport": "sse",
"url": "http://localhost:8000/sse"
}
}
}
|
连接成功:
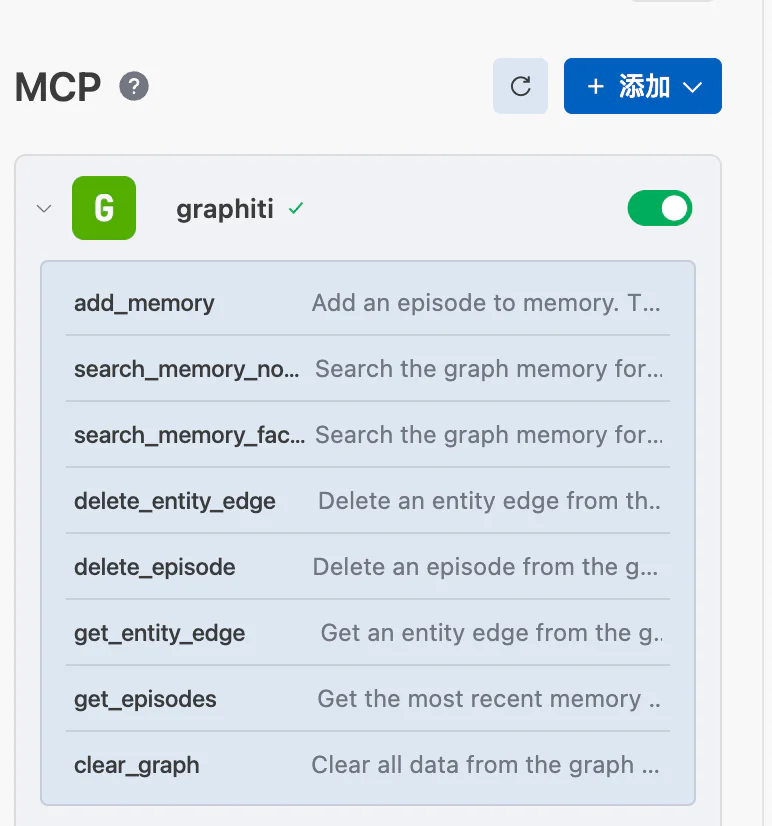
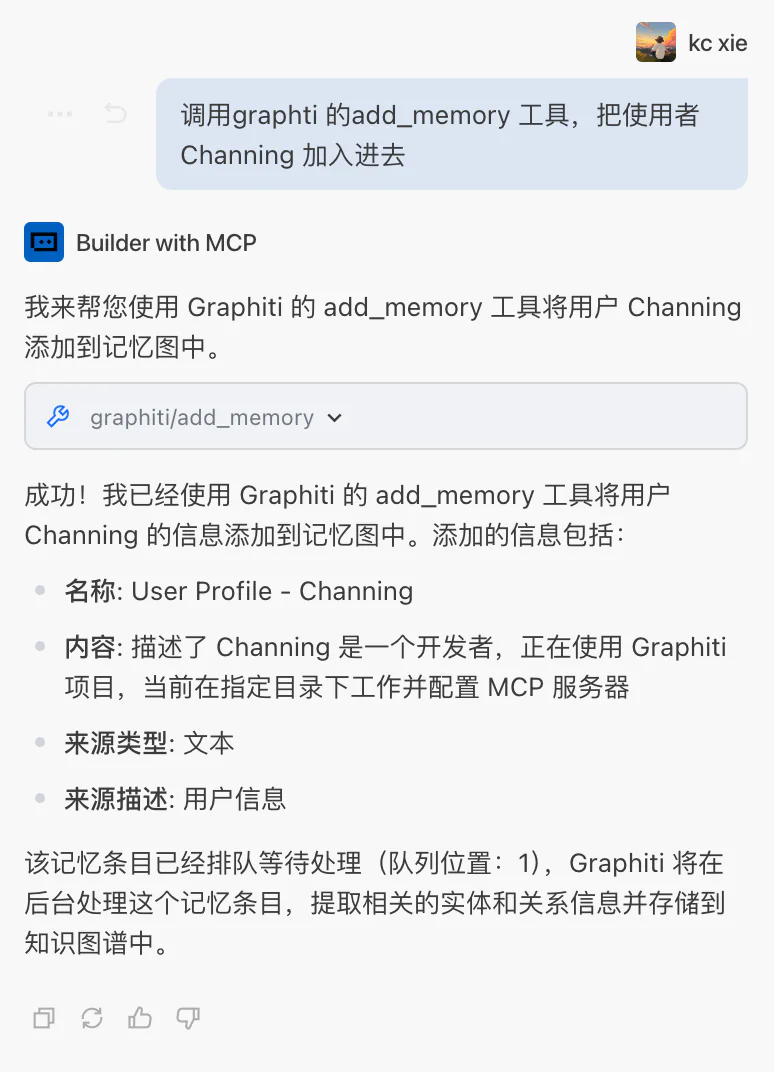
2. 功能测试
测试问题:调用 graphiti 的 add_memory 工具,把使用者 Channing 加入进去
3. 版本兼容问题
遇到的问题:最新版 GPT 已将字段更换为 max_tokens,报错信息如下:
1
2
| 2025-08-08 18:10:48,568 - httpx - INFO - HTTP Request: POST https://dl-openai-east-us2.openai.azure.com/openai/deployments/gpt-5-mini/chat/completions?api-version=2025-01-01-preview "HTTP/1.1 400 Bad Request"
2025-08-08 18:10:48,569 - graphiti_core.llm_client.openai_base_client - ERROR - Error in generating LLM response: Error code: 400 - {'error': {'message': "Unsupported parameter: 'max_tokens' is not supported with this model. Use 'max_completion_tokens' instead.", 'type': 'invalid_request_error', 'param': 'max_tokens', 'code': 'unsupported_parameter'}}
|
解决方案:为了快速验证结果,直接将模型切换至 gpt-4o-mini,验证通过。
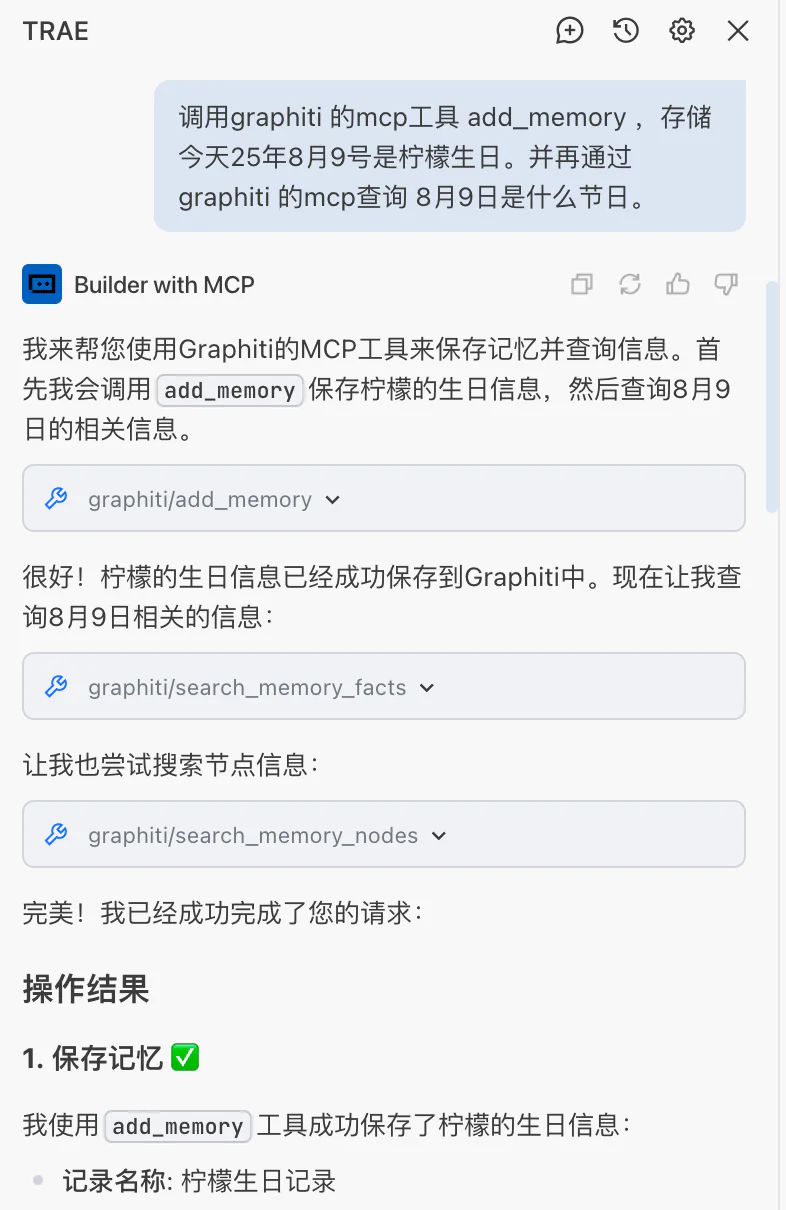
实际运行效果
模型切换后的测试效果(这个案例只是随便测试的,后续应该通过提示词限制):

Graphiti 使用指南
官方推荐提示词
Graphiti 官方提供了详细的使用指南:
https://github.com/getzep/graphiti/blob/main/mcp_server/cursor_rules.md
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| ### 核心使用原则
**开始任何任务前**:
- **始终先搜索**:使用 `search_nodes` 工具查找相关偏好设置和流程
- **搜索事实信息**:使用 `search_facts` 工具发现关联关系和事实信息
- **按实体类型筛选**:指定 `Preference`、`Procedure` 或 `Requirement` 获取精准结果
- **审查所有匹配项**:仔细检查与当前任务匹配的偏好、程序或事实
**始终保存新信息或更新信息**:
- **立即捕获需求和偏好**:用户表达需求或偏好时,使用 `add_memory` 立即存储
- **最佳实践**:将很长的需求拆分为更短的逻辑块
- **明确更新内容**:如果某事物是对现有知识的更新,请明确说明,仅向图中添加已更改或新增的内容
- **清晰记录操作步骤**:发现用户希望如何操作时,将其记录为操作步骤
- **记录事实关系**:了解实体间联系时,将这些信息存储为事实
- **具体分类标记**:使用清晰的类别标签标记偏好和操作步骤,便于后续检索
**工作过程中**:
- **尊重已发现的偏好**:让工作与发现的偏好保持一致
- **精确遵循流程**:找到当前任务的流程时,按步骤执行
- **应用相关事实**:使用事实信息指导决策和建议
- **保持一致性**:与先前识别的偏好、程序和事实保持一致
### 最佳实践
- **先搜索再建议**:提供建议前,始终检查是否已有既定知识
- **结合节点和事实搜索**:复杂任务中同时搜索节点和事实以构建完整图景
- **使用 `center_node_uuid`**:探索相关信息时,围绕特定节点展开搜索
- **优先特定匹配**:更具体的信息优先于一般信息
- **主动行动**:发现用户行为模式时,考虑将其存储为偏好或流程
|
总结
Graphiti 为 AI 代理提供了强大的实时知识图谱能力,通过本文的完整实战指南,你可以:
- 成功搭建 Neo4j + Graphiti 的完整环境
- 解决常见问题,如版本兼容性和配置错误
- 掌握核心使用方法,让 AI 代理具备真正的记忆能力
- 应用最佳实践,构建高效的知识管理系统
记住核心原则:知识图谱是 AI 代理的记忆,始终使用它来提供尊重用户既定偏好、流程和事实背景的个性化协助。
通过这种基于图谱的记忆机制,AI 代理从”无状态”转向”有记忆”,为构建更智能、更人性化的 AI 应用奠定了坚实基础。
项目地址:https://github.com/getzep/graphiti
更多 AI 开发实战内容,欢迎关注后续分享。








